
News
- [03/2026]Two papers accepted to CVPR 2026!
- [02/2026]We present Seed 2.0 Pro, which ranks 3rd on the Vision Arena.
- [07/2025]Four papers accepted to ICCV 2025!
- [06/2025]Journal extension of UniRepLKNet is accepted to IEEE TPAMI.
- [02/2024]Four papers accepted to CVPR 2024.
- [10/2023]Meta-Transformer was officially reported by MIT TechReview.
Work Experience
ByteDance, Seed-VL Team
- Core contributors, in Doubao-1.5-Pro-Vision, Seed1.5-VL, Seed-1.8, and Seed-2.0.
- Foundation model team of VLM @ Bytedance Seed.
- Working on VLM architecture, pretraining, video understanding, and unified understanding & generation.


Education
The Chinese University of Hong Kong
PhD in Department of Information Engineering (MMLab)
08/2023 - 06/2027 (Expected)
Hong Kong
Beijing Institute of Technology
Bachelor in Artificial Intelligence
36th XuTeLi Scholarship (Top 10/8000+)
09/2019 - 06/2023
Beijing
Research Publications
Categorized by theme. Full list on Google Scholar.
Multimodal Scalability
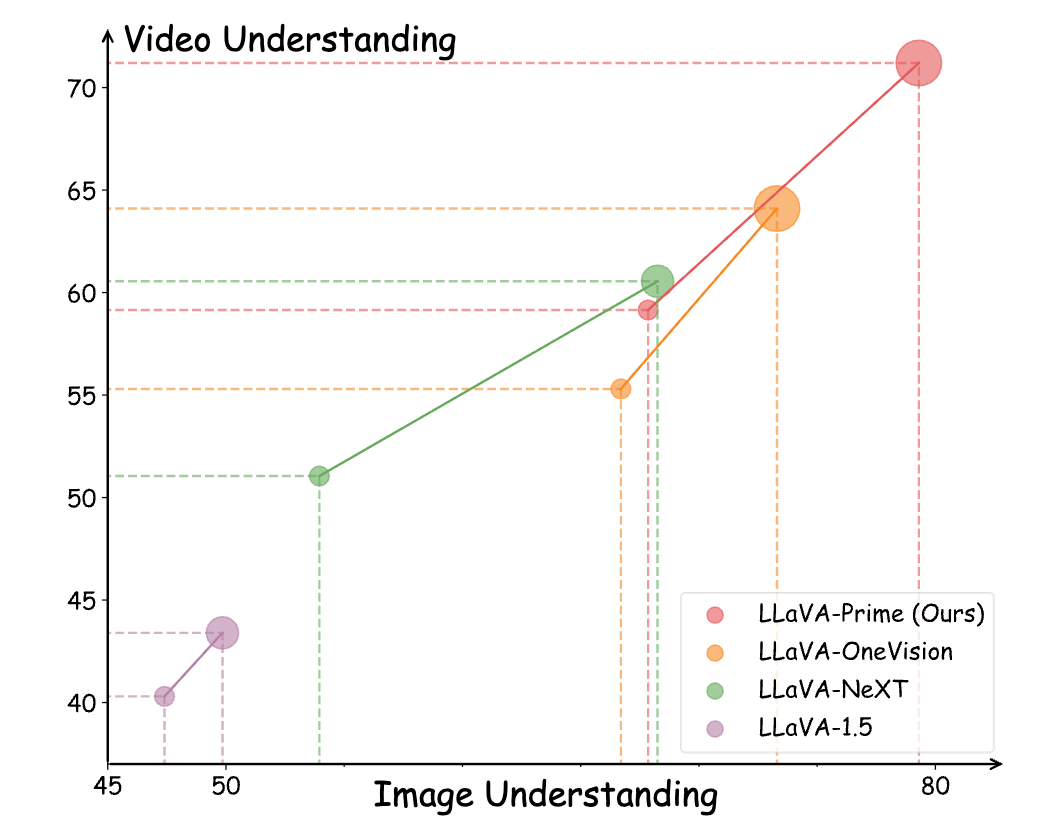
Learning Beyond Still Frames: Scaling Vision-Language Models with Video
Yiyuan Zhang, Handong Li, Jing Liu, Xiangyu Yue
ICCV 2025. IEEE
Explores the scaling laws of integrating continuous video data into existing VLM architectures.
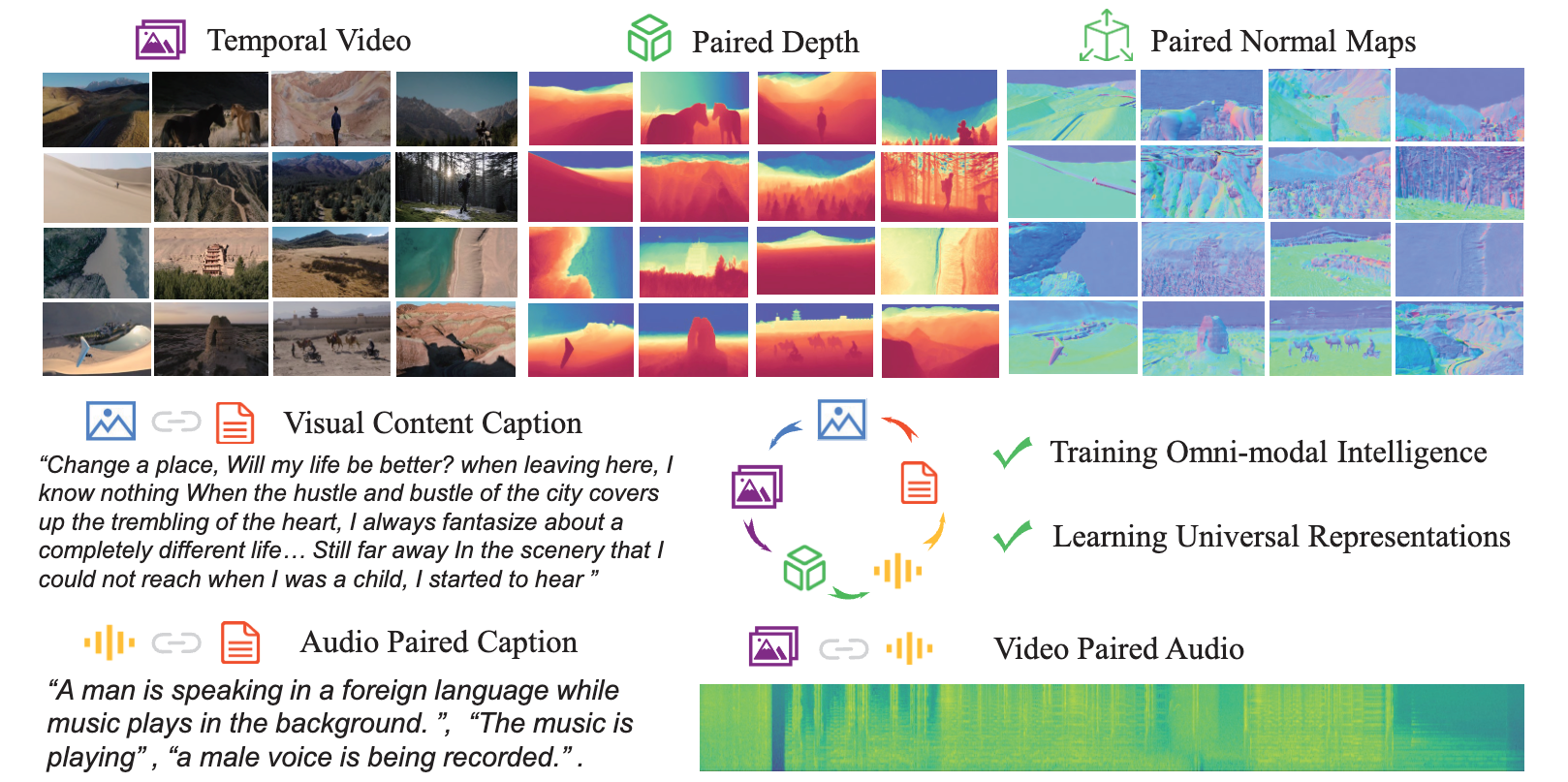
Multimodal Simplicity
![[1] Meta-Transformer: A Unified Framework for Multimodal Learning](/images/metatransformer_banner.png)
[1] Meta-Transformer: A Unified Framework for Multimodal Learning
Yiyuan Zhang, Kaixiong Gong, Kaipeng Zhang, Hongsheng Li, Wanli Ouyang, Yu Qiao, Xiangyu Yue
Arxiv Preprint
We found a unified framework performing multimodal learning across 12 modalities. Featured by MIT TechReview.
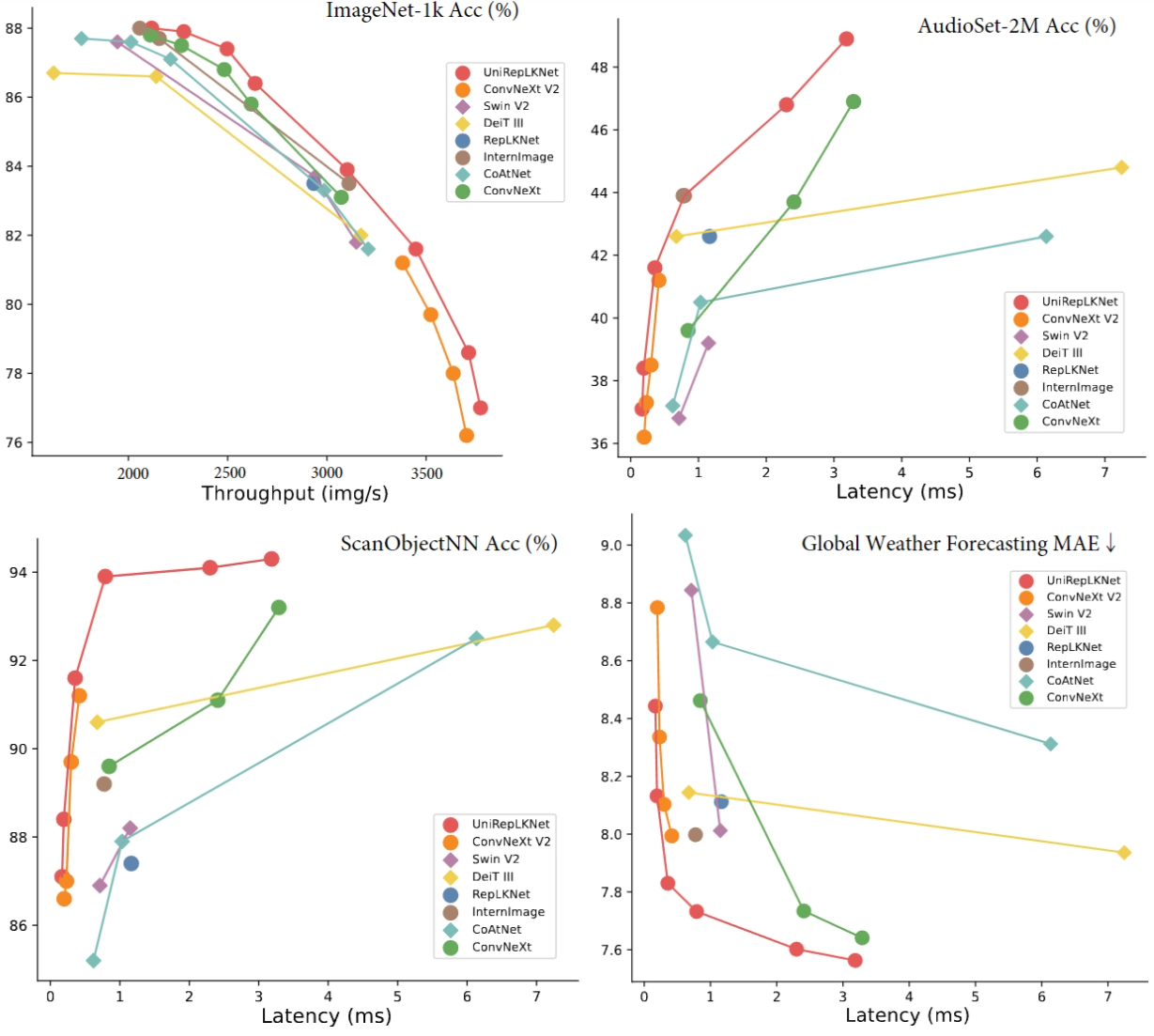
![[2] UniRepLKNet: A Universal Perception Large-Kernel ConvNet for Audio Video Point Cloud Time-Series and Image Recognition](/images/unireplknet_banner.png)
[2] UniRepLKNet: A Universal Perception Large-Kernel ConvNet for Audio Video Point Cloud Time-Series and Image Recognition
Xiaohan Ding*, Yiyuan Zhang*, Yixiao Ge, Sijie Zhao, Lin Song, Xiangyu Yue, Ying Shan
CVPR 2024. IEEE
We further explore the universal modeling capacity of Transformers and propose a universal perception large-kernel convnet for multimodal recognition.
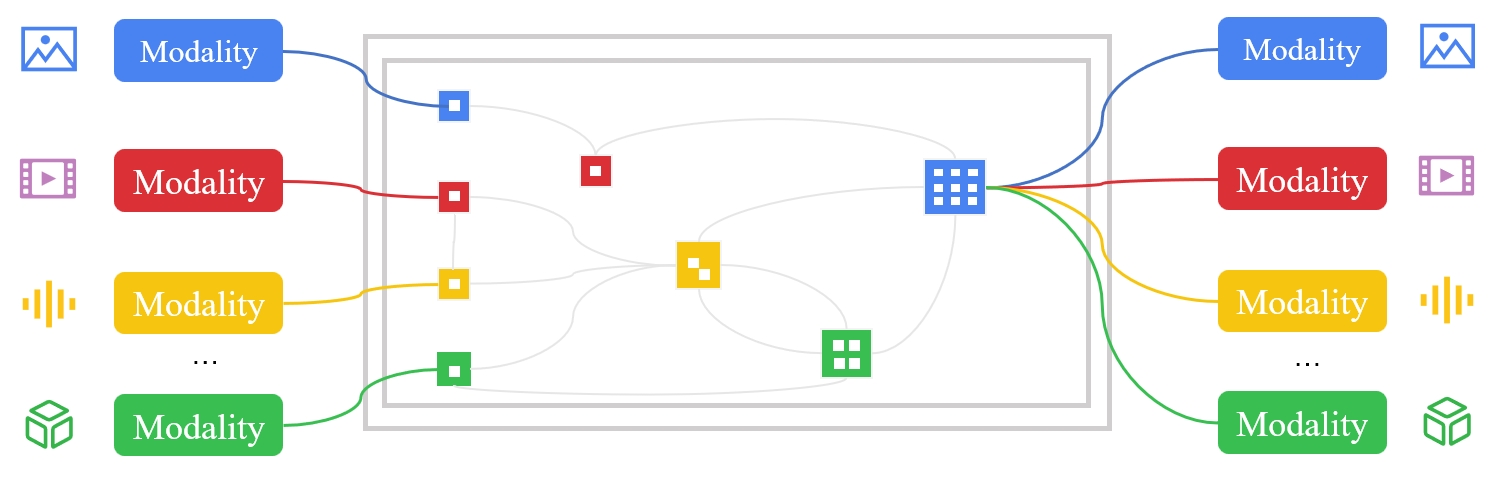
![[3] OneLLM: One Framework to Align All Modalities with Language](/images/onellm_banner.png)
![[4] OneThinker: All-in-one Reasoning Model for Image and Video](/images/onethinker_banner.png)
[4] OneThinker: All-in-one Reasoning Model for Image and Video
Kaituo Feng, Manyuan Zhang, Hongyu Li, Kaixuan Fan, Shuang Chen, Yilei Jiang, Dian Zheng, Peiwen Sun, Yiyuan Zhang, Haoze Sun, Yan Feng, Peng Pei, Xunliang Cai, Xiangyu Yue
CVPR 2026. IEEE
We propose a unified reasoning model for image and video understanding, which achieves state-of-the-art performance on various vision-language reasoning tasks.
Multimodal System
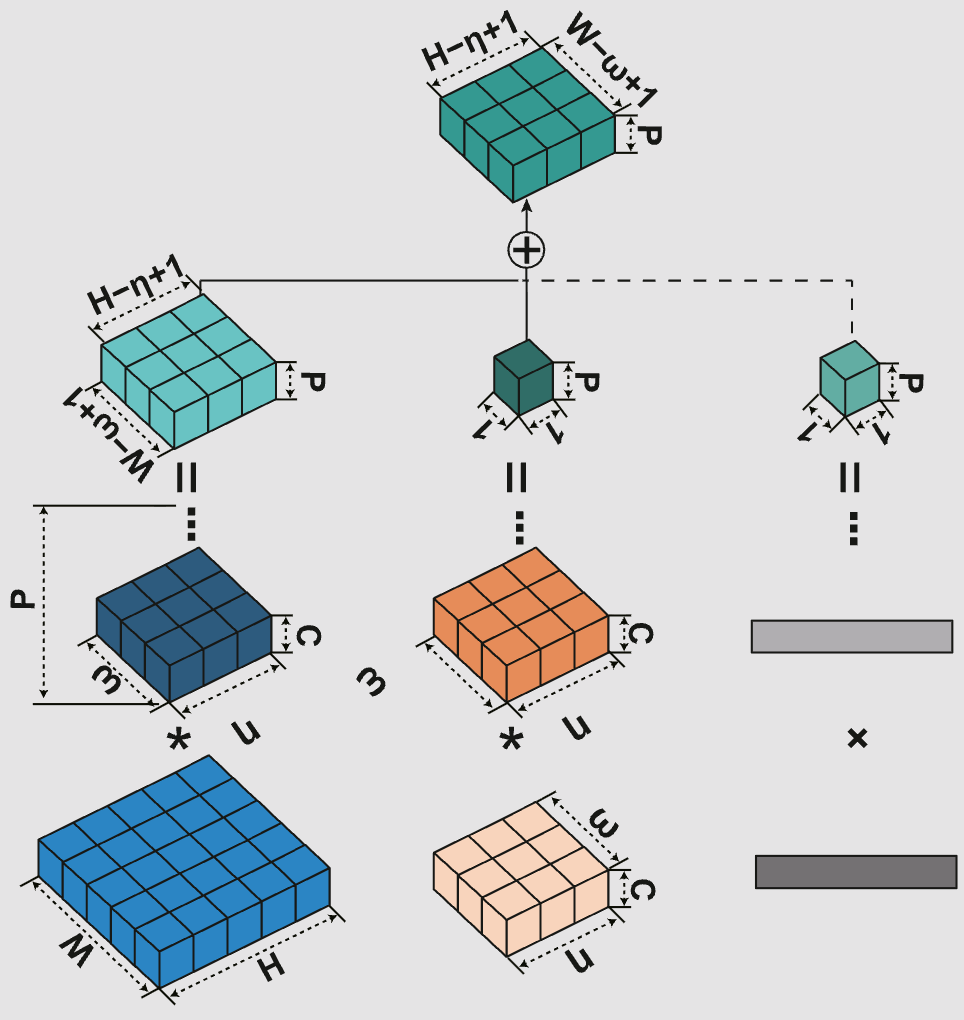
Asymmetric Convolution: An Efficient and Generalized Method to Fuse Feature Maps in Multiple Vision Tasks
Wencheng Han, Xingping Dong, Yiyuan Zhang, David Crandall, Cheng-Zhong Xu, Jianbing Shen
IEEE Transactions on Pattern Analysis and Machine Intelligence 2024.
A generalized feature fusion method accelerating multiple down-stream vision tasks.
Open-Source Impact
Simple Scaling-S1
Main Contributor
Meta-Transformer
Projector Owner
UniRepLKNet
Projector Owner
OneLLM
Main Contributor
Professional Service
- Conference Reviewer: CVPR, NeurIPS, ICML, ICLR, ICCV, ECCV, AAAI, etc.
- Journal Reviewer: IEEE TPAMI, TIP, TNNLS, IJCV, etc.
- Invited Talks: OpenMMlab, TechBeat, etc.