
1) We note that most architectures of the existing large-kernel ConvNets simply follow other models. The architectural design for large-kernel ConvNets remains under-explored.
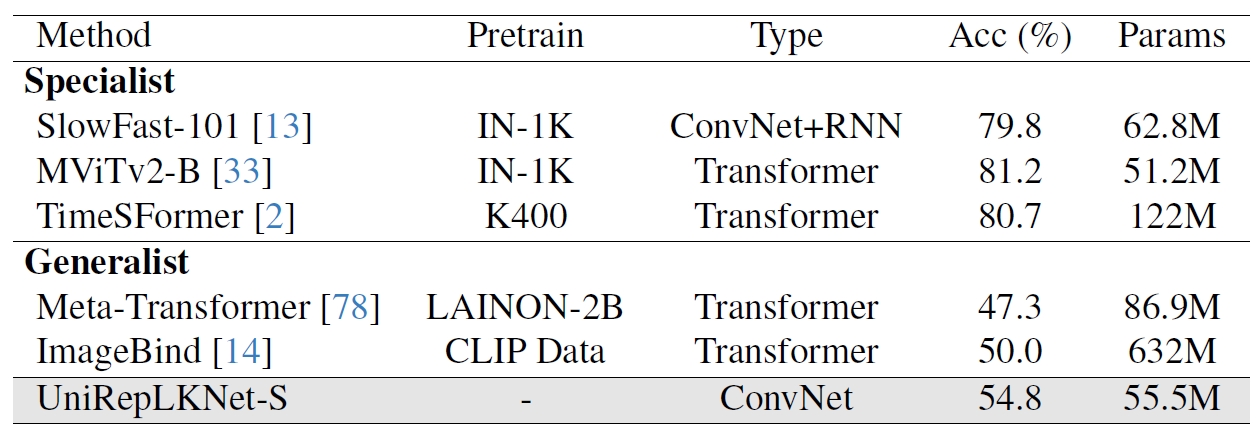
2) The universal perception ability of Transformers is sparking in multimodal research areas (image, audio, video, time-series, etc). We are curious whether ConvNets can also deliver universal perception ability across multiple modalities with a unified architecture.
1) We propose four architectural guidelines for designing large-kernel ConvNets, the core of which is to exploit the essential characteristics of large kernels that distinguish them from small kernels - they can see wide without going deep. Following such guidelines, our proposed large-kernel ConvNet shows leading performance in image recognition. For example, our models achieve an ImageNet accuracy of 88.0%, ADE20K mIoU of 55.6%, and COCO box AP of 56.4%, demonstrating better performance and higher speed than a number of recently proposed powerful competitors.
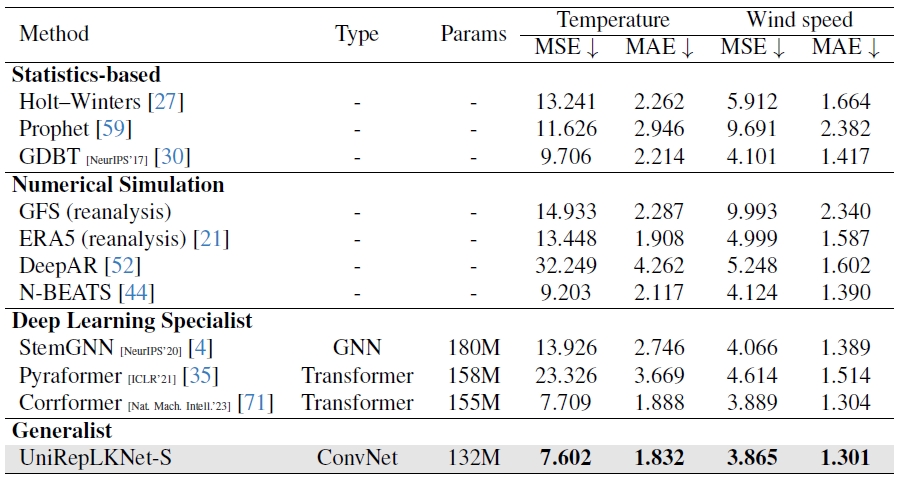
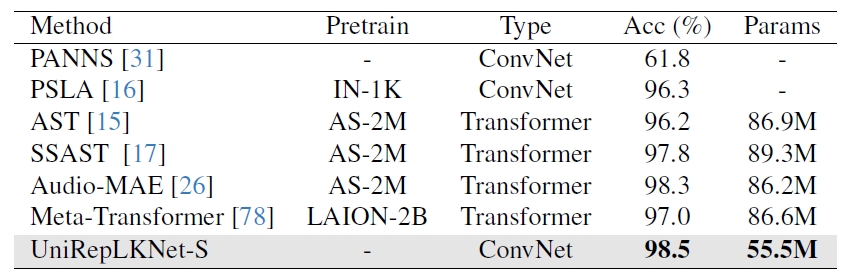
2) We discover that large kernels are the key to unlocking the exceptional performance of ConvNets in domains where they were originally not proficient. With certain modality-related preprocessing approaches, the proposed model achieves state-of-the-art performance on time-series forecasting and audio recognition tasks even without modality-specific customization to the architecture.
Architectural design of UniRepLKNet. A LarK Block comprises a Dilated Reparam Block proposed in this paper, an SE Block, an FFN, and Batch Normalization (BN) layers. The only difference between a SmaK Block and a LarK Block is that the former uses a depth-wise 3×3 conv layer in replacement of the Dilated Reparam Block in the latter. Stages are connected by downsampling blocks implemented by stride-2 dense 3×3 conv layers.
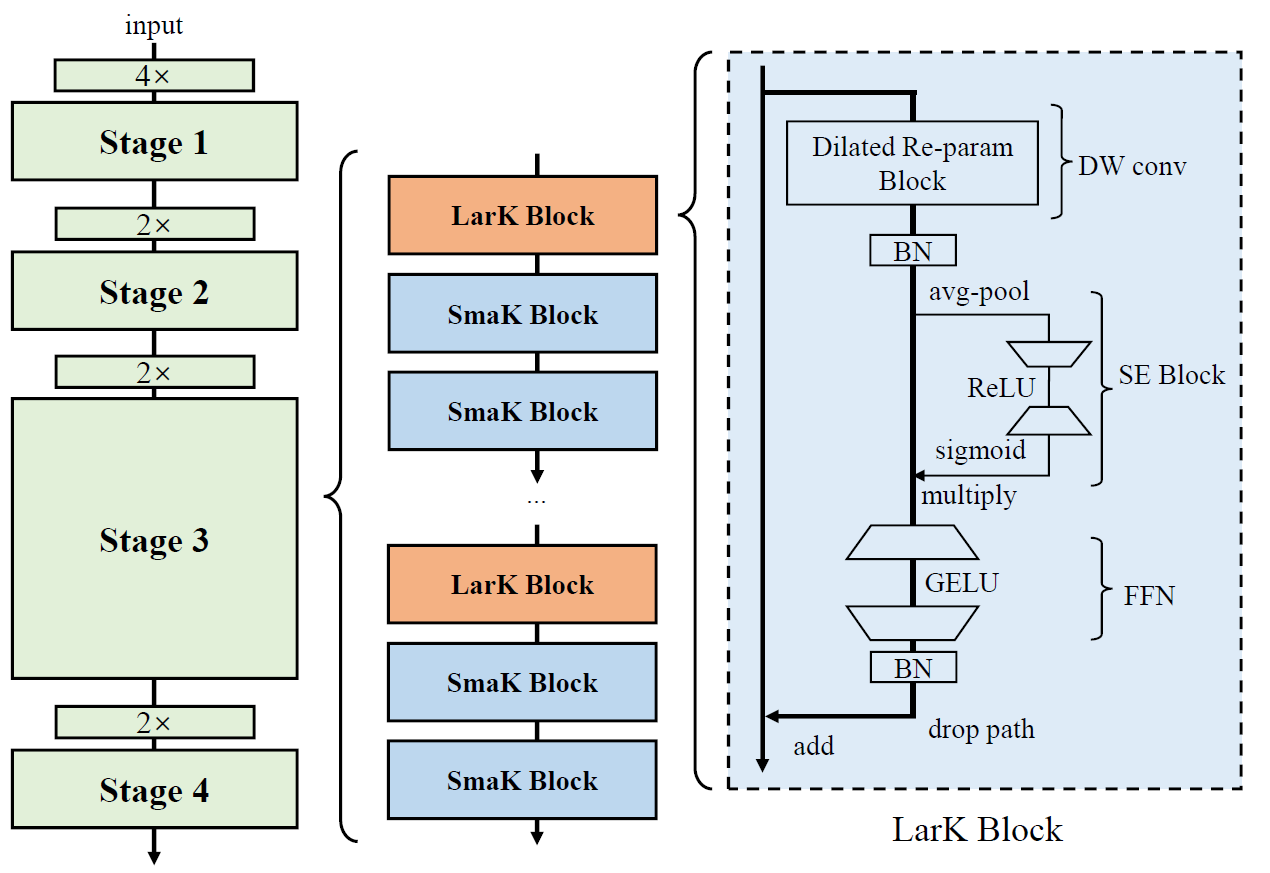
More details on architectural designs, please refer our Paper,
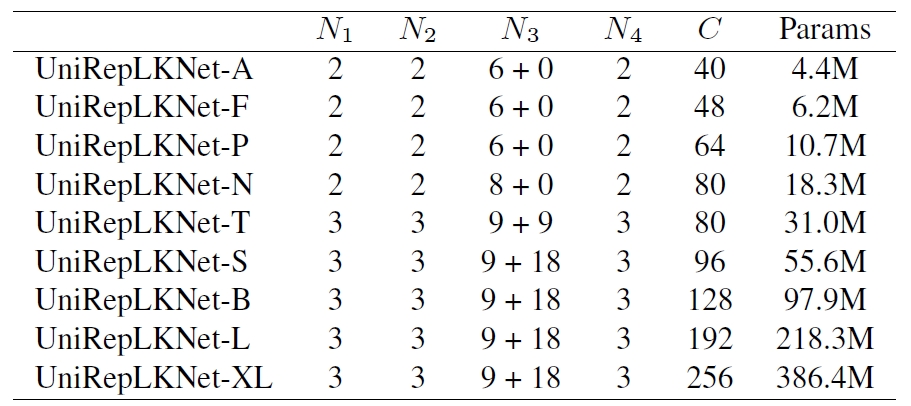
Architectural hyper-parameters of UniRepLKNet instances, including the number of blocks in the four stages N1,N2,N3,N4 and channels C of the first stage. Stage 1 uses SmaK Blocks, and Stages 2 and 4 use LarK Blocks only. For Stage 3, e.g., “9 + 18” means 9 LarK Blocks and 18 SmaK Blocks.
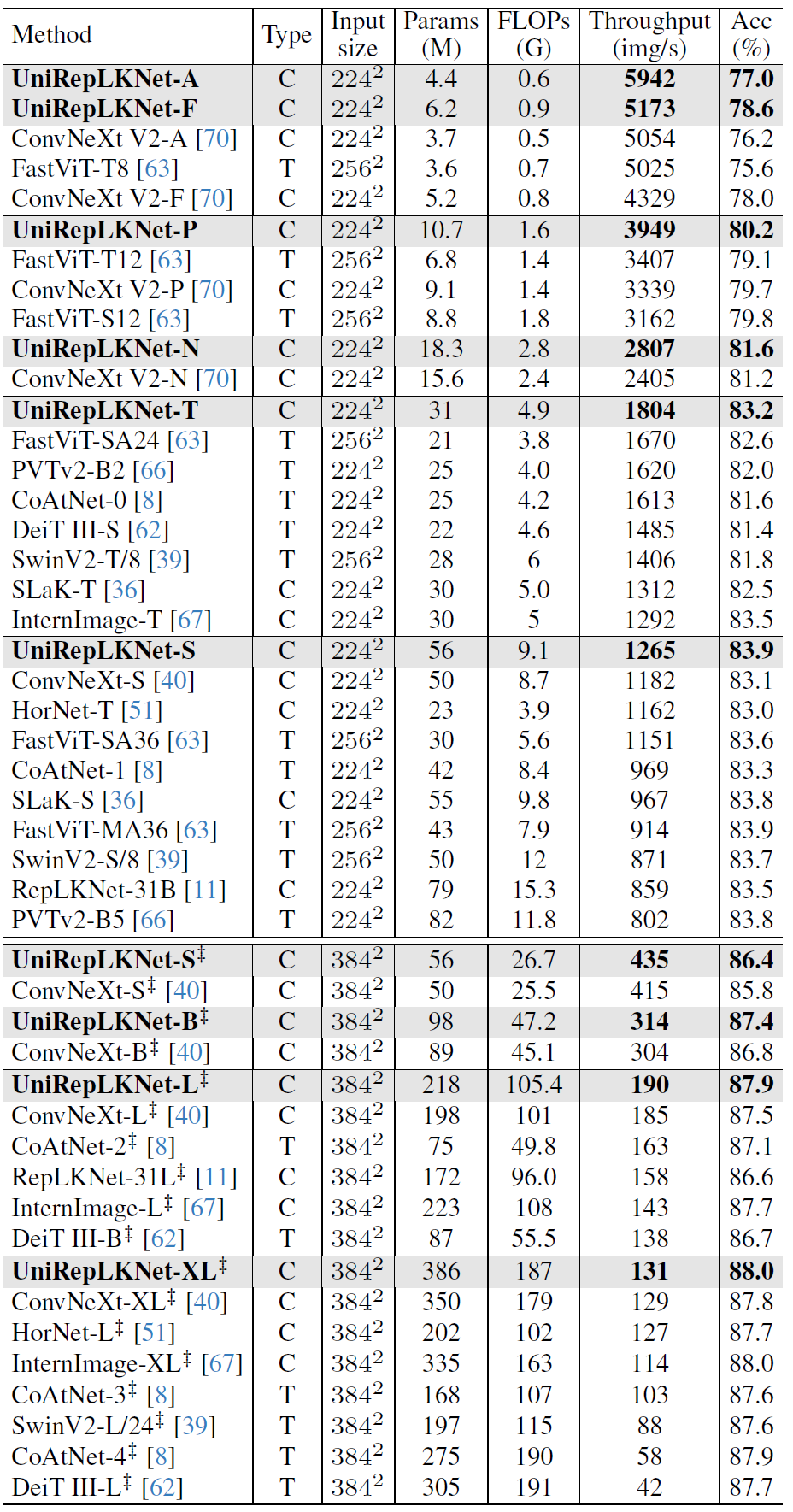
1) UniRepLKNet-A/F outperforms ConvNeXt-V2-A/F by 0.8/0.6 in the accuracy and runs 19%/17% faster, respectively.
2) UniRepLKNet-P/N outperforms FastViT-T12/S12 and ConvNeXt V2-P/N by clear margins.
3) UniRepLKNet-T outperforms multiple small-level competitors.
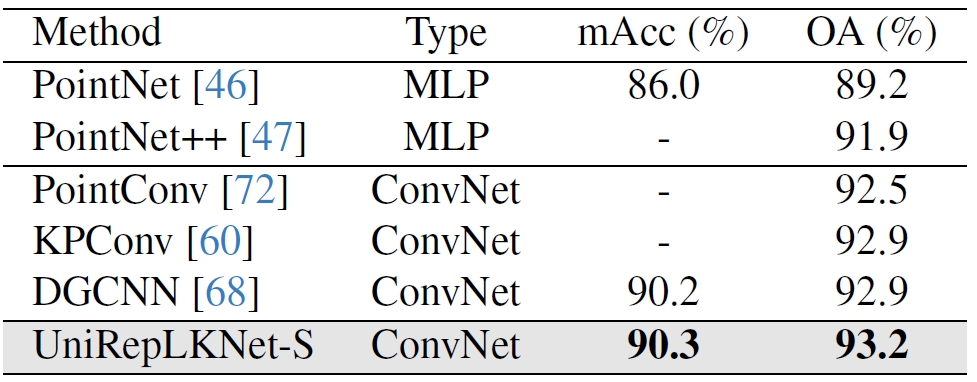
4) UniRepLKNet-S outperforms a series of small-level and even base-level models in both speed and accuracy and runs almost as fast as InternImage-T.
5) With ImageNet-22K pretraining, UniRepLKNet-S even approaches the accuracy of RepLKNet-31L and runs 3× as fast as the latter. UniRepLKNet-B outperforms CoAtNet- 2 and DeiT III-B by clear margins. UniRepLKNet-L outperforms InternImage-L in both accuracy and throughput.
6) On the XL-level, UniRepLKNet-XL outperforms in both accuracy and throughput, running more than 2× as fast as CoAtNet-3 and 3× as DeiT III-L.
Object detection on COCO validation set. FLOPs are measured with 1280×800 inputs. “‡” ImageNet-22K pretraining.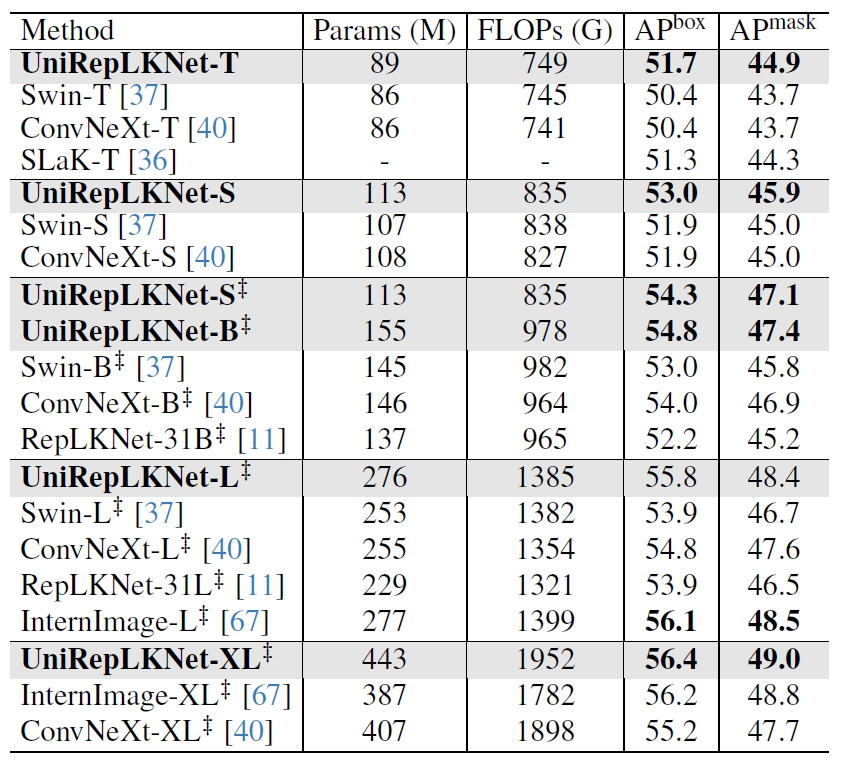
We transfer the pretrained UniRepLKNets as the backbones of Cascade Mask R-CNN [3, 20] and adopt the standard 3x (36-epoch) training configuration with MMDetection. UniRepLKNet outperforms Swin,ConvNeXt, RepLKNet, and SLaK, which are representatives of ViTs, modern medium-kernel ConvNets, and existing large-kernel ConvNets, respectively, and shows comparable performance to InternImage
Semantic segmentation on ADE20K validation set. The FLOPs are measured with 512×2048 or 640×2560 inputs according to the crop size. “SS” and “MS” mean single- and multiscale testing, respectively. “‡” indicates ImageNet-22K [9] pretraining.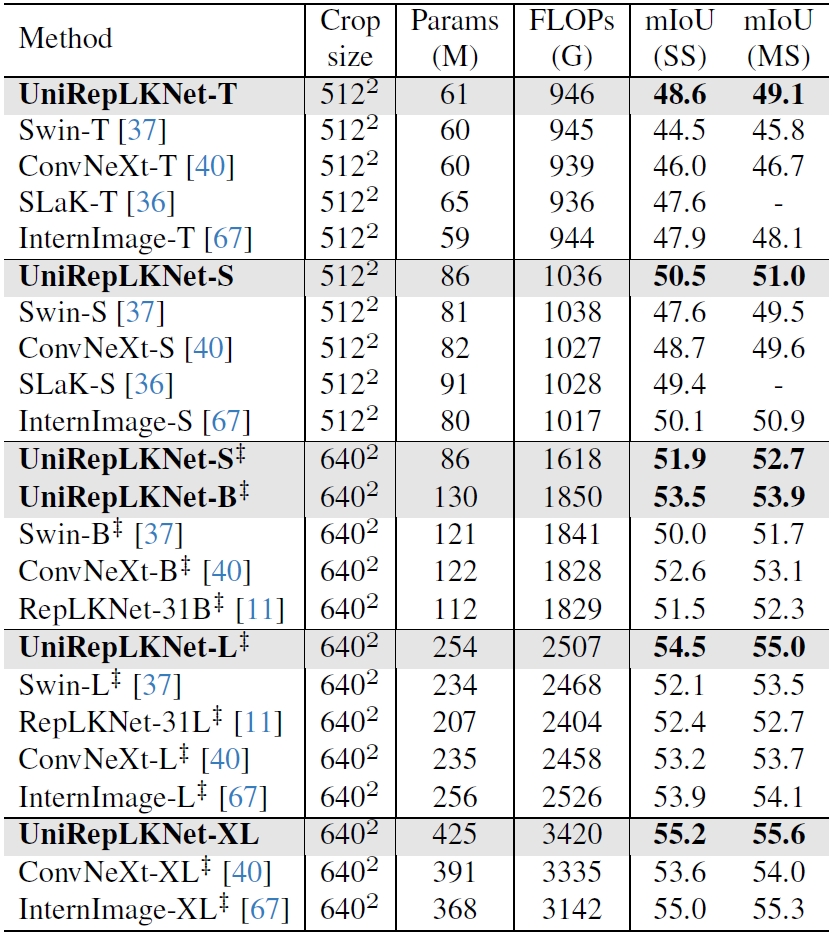
We use the pretrained UniRepLKNets as the backbones of UPerNet on ADE20K and adopt the standard 160k-iteration training receipt with MMSegmentation. It reports the mIoU on the validation set. Impressively, UniRepLKNet outperforms InternImage and the other models.
@article{ding2023unireplknet,
title={UniRepLKNet: A Universal Perception Large-Kernel ConvNet for Audio, Video, Point Cloud, Time-Series and Image Recognition},
author={Ding, Xiaohan and Zhang, Yiyuan and Ge, Yixiao and Zhao, Sijie and Song, Lin and Yue, Xiangyu and Shan, Ying},
journal={arXiv preprint arXiv:2311.15599},
year={2023}
}